Las matemáticas detrás de la detección de ‘malware’
Los algoritmos de aprendizaje automático se entrenan con grandes cantidades de datos (ya resueltos) para después predecir ciertas características de datos nuevos

Los virus informáticos conocidos como software malicioso (o malware) son una seria amenaza para usuarios, empresas u organizaciones gubernamentales. Generalmente, se comportan de manera similar a una persona perversa: puede parecer maravillosa, pero en realidad ser muy dañina; quedarse en silencio y arremeter poco a poco; unirse con otras para atacar a una persona concreta; u obtener información confidencial de la víctima (secretos personales) y usarla para estafarla. Hoy en día, para detectarlos y minimizar los daños ocasionados, se emplean algoritmos matemáticos de aprendizaje automático.
Los antivirus tradicionales se basaban en identificar cada virus con una cadena de caracteres de longitud fija (HASH), obtenida al aplicar un algoritmo de encriptación. El programa almacenaba estas cadenas en una lista negra y cuando analizaba un fichero nuevo, obtenía su HASH correspondiente y buscaba coincidencias en la lista; si se encontraba alguna, saltaba una alarma. Pero en la actualidad, el malware es más avanzado y es capaz de mutar evitando ser detectado, por lo que no basta con este método, sino que se hace uso de herramientas de aprendizaje automático.
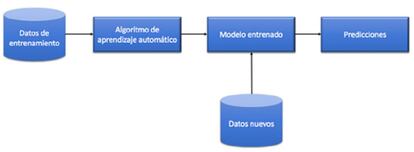
Los algoritmos matemáticos de aprendizaje automático se entrenan con grandes cantidades de datos (ya resueltos) para después predecir ciertas características de datos nuevos, como se muestra en la Figura 1. Por ejemplo, un algoritmo de reconocimiento facial emplea millones de fotos en las que se ha identificado una cara para establecer un cierto patrón, de manera que cuando se introduzca una foto cualquiera, este podrá predecir dónde se encuentra una posible cara.
El proceso automático de detección de malware se basa en extraer ciertas características de un tipo de virus, como el número de registros, tamaño, instrucciones o entropía (el grado de desorden), y también de su comportamiento (las conexiones que realiza, accesos a ficheros, procesos que ejecuta…). Una vez obtenidas, se aplica un algoritmo matemático que aprende el comportamiento de estas características, y crea un modelo general para detectar los virus.
Entre los algoritmos más conocidos se encuentra el llamado clasificador Bayesiano ingenuo. Se basa en el teorema de Bayes, que expresa la probabilidad de que suceda un evento aleatorio (A), condicionado a que haya sucedido otro (B). En el caso de la detección de malware, el algoritmo crea un modelo a partir de archivos clasificados como malware e inofensivos. Para ello, se extraen las características de los archivos (B), y se calculan las probabilidades de que aparezcan cuando un fichero es malware (A) y cuando es inofensivo (A’). Para clasificar un fichero nuevo, se calcula la probabilidad de que este pueda ser malware (A) e inofensivo (A´), dependiendo de las características que muestre (B); si la primera probabilidad es mayor que la segunda, el fichero se considera malware.
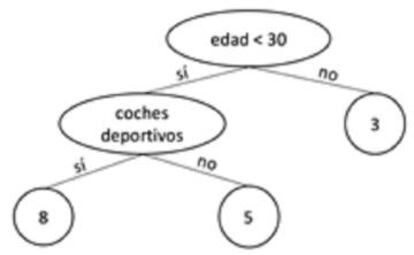
También se utilizan los algoritmos basados en arboles de decisión, diagramas que representan condiciones lógicas que ocurren de manera sucesiva, llevando a una u otra solución dependiendo de las reglas aplicadas. Un ejemplo se puede ver en la Figura 2.
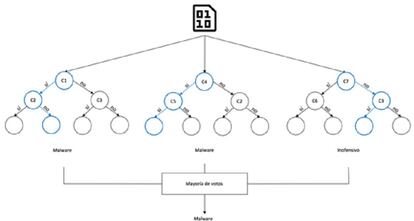
Un algoritmo popular en ciberseguridad es el de Bosques Aleatorios (Random Forest). Éste crea árboles de decisión seleccionando un subgrupo de características del malware de manera aleatoria. Cada árbol contiene unas características específicas; si estas son más frecuentes en ficheros maliciosos, se etiqueta como tal, y como inofensivo en caso contrario. Cuando se analiza un fichero nuevo, cada árbol expresa su preferencia (o voto), es decir, cómo lo clasificaría dependiendo de sus características. Por ejemplo, si el fichero nuevo presenta las características del árbol 1 y éste se encuentra etiquetado como inofensivo, el árbol 1 clasificará el fichero nuevo cómo inofensivo. Finalmente, se toma la decisión que ha obtenido mayoría de votos, cómo se puede apreciar en la Figura 3.
En la actualidad aparece otro inconveniente: la presencia de uno o varios adversarios que pueden pasar desapercibidos y hacer que los algoritmos de detección fallen. Los adversarios pueden atacar de diferentes formas: “envenenando” los datos para introducir información errónea, por ejemplo, afirmar que un malware es inofensivo; realizando ataques de evasión, modificando el malware de manera intencionada para confundir al algoritmo; o ataques de inferencia, basados en producir malware que trata de encontrar los límites de detección del algoritmo.
Como contramedida, los modelos avanzados de Análisis de Riesgos Adversarios (ARA) buscan modelizar la incertidumbre de los atacantes haciendo uso de análisis de riesgos y teoría de juegos, teniendo en cuenta que los adversarios son racionales, aunque en ciertas ocasiones no tienen por qué actuar de forma racional. Hoy en día, grupos de investigación de todo el mundo, y proyectos como CYBECO, trabajan para mejorar estas herramientas y con ellas aumentar la seguridad de los sistemas informáticos.
Alberto Redondo Hernández es estudiante de doctorado en la Universidad Autónoma de Madrid y miembro del Instituto de Ciencias Matemáticas.
Café y Teoremas es una sección dedicada a las matemáticas y al entorno en el que se crean, coordinado por el Instituto de Ciencias Matemáticas (ICMAT), en la que los investigadores y miembros del centro describen los últimos avances de esta disciplina, comparten puntos de encuentro entre las matemáticas y otras expresiones sociales y culturales, y recuerdan a quienes marcaron su desarrollo y supieron transformar café en teoremas. El nombre evoca la definición del matemático húngaro Alfred Rényi: "Un matemático es una máquina que transforma café en teoremas".
Edición y coordinación: Ágata Timón (ICMAT)
Tu suscripción se está usando en otro dispositivo
¿Quieres añadir otro usuario a tu suscripción?
Si continúas leyendo en este dispositivo, no se podrá leer en el otro.
FlechaTu suscripción se está usando en otro dispositivo y solo puedes acceder a EL PAÍS desde un dispositivo a la vez.
Si quieres compartir tu cuenta, cambia tu suscripción a la modalidad Premium, así podrás añadir otro usuario. Cada uno accederá con su propia cuenta de email, lo que os permitirá personalizar vuestra experiencia en EL PAÍS.
¿Tienes una suscripción de empresa? Accede aquí para contratar más cuentas.
En el caso de no saber quién está usando tu cuenta, te recomendamos cambiar tu contraseña aquí.
Si decides continuar compartiendo tu cuenta, este mensaje se mostrará en tu dispositivo y en el de la otra persona que está usando tu cuenta de forma indefinida, afectando a tu experiencia de lectura. Puedes consultar aquí los términos y condiciones de la suscripción digital.




























































