Las máquinas entrenadas con datos artificiales llevan al colapso de la IA: “Pierden la percepción de la realidad”
La pérdida de calidad del contenido y la perpetuación de los sesgos son algunas consecuencias de este bucle en los modelos de inteligencia artificial


Si se le pide a un modelo de inteligencia artificial (IA) que genere imágenes de perros al azar, la máquina va a recrear las imágenes de un golden retriever como la raza de perro más popular, pero también algunos dálmatas o bulldogs franceses, aunque en menor cantidad por ser razas más raras. Pero si otros modelos de IA se entrenaran con los datos producidos por esa máquina, con el golden retriever sobrerrepresentado, poco a poco se olvidarán de las razas menos comunes y solo mostrarán esa raza. Finalmente, devolverán únicamente manchas marrones que se asemejan a esos perros. Una investigación demuestra que después de entrenar una y otra vez a un modelo de IA con contenido generado por la misma máquina, el modelo colapsa, dejando así de funcionar, dando malas respuestas y proporcionando información incorrecta. “Empiezan a producir ejemplos que nunca serían creados por el modelo original, es decir, empiezan a malinterpretar la realidad basándose en errores introducidos por sus predecesores”, explica el estudio que alerta de cómo las máquinas que se entrenan con información sintética “pierden la percepción de la realidad”.
“Empieza a perder información porque no está claro si los datos recogidos son suficientes para cubrir todos los casos posibles. Los modelos están sesgados e introducen sus propios errores, y los modelos del futuro pueden percibir erróneamente la realidad, ya que se entrenarán con datos sesgados procedentes de otros modelos”, explica Ilia Shumailov, coautor del estudio publicado hoy en la revista Nature, punta de lanza de la mejor ciencia, e investigador de la Universidad de Oxford, que actualmente trabaja para Google DeepMind. Los datos se “envenenan”, según expresa el estudio.
Los autores del estudio presentan unos modelos matemáticos que ilustran la idea del colapso: demuestran que una IA puede pasar por alto algunos datos en su entrenamiento (por ejemplo, líneas de texto menos comunes) y solo entrenarse con una parte de ellos. Por ejemplo, se hizo una prueba con un texto sobre arquitectura medieval como entrada original y en el noveno entrenamiento terminó dando una lista de liebres. “Los modelos aprenden unos de otros. Cuánto más aprenden, más degradan su rendimiento y empiezan a generar texto repetitivo que es independiente de la petición de entrada”, añade Shumailov.
Hoy en día es una práctica habitual que los modelos se entrenen con datos sintéticos, aquellos que no han sido creados por humanos, sino que imitan datos del mundo real. Así lo señala el último informe de ChatGPT-4 de OpenAI. En principio, sería casi imposible distinguir si los datos han sido generados por máquinas o humanos, pero si no se toman medidas para controlar el colapso, las consecuencias son “la degradación de la calidad del contenido, la contaminación de datos, y la perpetuación de los sesgos”, describe Luis Herrera, arquitecto de soluciones en Databricks España.
¿Por qué las empresas tecnológicas que están detrás de los modelos de lenguaje permiten estas prácticas? “Las IA son entrenadas con enormes cantidades de datos presentes en internet, producidos por personas que tienen derechos legales de autoría de su material. Para evitar demandas judiciales o para ahorrar costes, las empresas tecnológicas utilizan datos generados por sus propias IA para seguir entrenando sus máquinas”, explica Víctor Etxebarria, catedrático de la Universidad del País Vasco, en declaraciones al portal especializado SMC España. Sin embargo, añade: “Este procedimiento cada vez más generalizado hace que las IA no sirvan para ninguna función realmente fiable. Transforma las IA en herramientas no solo inútiles para ayudarnos a solucionar nuestros problemas, sino que puedes ser nocivas, si basamos nuestras decisiones en información incorrecta”.
El contenido creado puede ser utilizado para entrenar a otros modelos o incluso para entrenarse a ellos mismos. Incluso el bucle de degradación puede empezar de forma involuntaria, cuando las máquinas se entrenan con contenidos de internet, pero que han sido vertidos a su vez por otras máquinas. Lorena Jaume-Palasí, experta en ética algorítmica y asesora del Parlamento Europeo, alerta sobre peligro del origen de los datos sintéticos: “El buscador de Google es uno de los sitios en los que la calidad ha decrecido. Hay una gran variedad en la procedencia de este tipo de datos y la calidad en ningún momento puede ser buena. Son trillones de datos humanamente imposibles de corregirlos todos”. Y hace hincapié en el “colapso ecológico” que provoca estos modelos: “Los centros de datos se están llevando toda el agua. Va a llegar un momento en que vamos a tener que decidir a quién le damos agua y a quién no”.
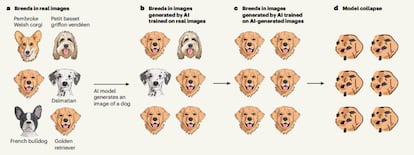
Pablo Haya Coll, investigador de la Universidad Autónoma de Madrid, destaca una limitación de estos sistemas: “Esta técnica puede llevar a corromper el LLM [un gran modelo de lenguaje, como ChatGPT, por sus siglas inglesas]. Es un aviso sobre la calidad de los datos utilizados en la construcción de estos LLM. A medida que se adoptan más estos LLM, más datos sintéticos terminan en internet, lo que podría afectar hipotéticamente a los entrenamientos de versiones futuras”.
Las conclusiones del estudio plantean un escenario donde solo se utilizan datos generados por la IA. En un contexto real, es probable que siempre haya una parte de los datos generados por humanos: como mínimo, los que hay disponibles ahora. Pero todavía no está claro cómo se pueden diferenciar esos datos. Shumailov, autor principal del estudio, sugiere que se haga con “el mantenimiento de listas y las marcas de agua”.
Para este investigador y sus colegas, entrenar un modelo con datos generados sintéticamente es posible, pero el filtrado debe tomarse muy en serio. Toju Duke, exdirectora de IA responsable de Google, explicaba a EL PAÍS en octubre del año pasado que se pueden entrenar a los modelos con datos generados por IA, siempre y cuando entre la regulación en juego: “Tenemos que ser capaces de comprobar los hechos y las fuentes. Tenemos que poder revisar estas cosas antes de lanzarlas. No podemos simplemente dejar que salgan, eso es una locura”.
Puedes seguir a EL PAÍS Tecnología en Facebook y X o apuntarte aquí para recibir nuestra newsletter sema c




























































