Los algoritmos tienen prejuicios: ellos son informáticos y ellas, amas de casa
La inteligencia artificial puede ser sexista. Cinco científicos nos explican por qué.

Es una verdad mundialmente reconocida que un hombre soltero, poseedor de una gran fortuna, necesita una esposa”. Así arrancó Jane Austen su famosa novela Orgullo y Prejuicio (1813). Preguntemos a un algoritmo que estudia el perfil psicológico y que ha desarrollado por la Universidad de Cambridge, a cien millas de donde vivió la escritora inglesa, qué nos diría al analizar ese pequeño texto.
- La persona que lo escribió es más liberal y artística que la media… ¡Correcto!
- Es más organizada y trabajadora también… ¡Correcto!
- Su edad ronda los 30 años… Aproximado
- La probabilidad de que sea un hombre es del 99%… ¿Jane Austen?
¿Un error casual? Pongamos a prueba al mismo algoritmo con otra mujer, esta vez de la época presente; Christine Lagarde. ¿Qué conclusiones extrae tras analizar un discurso suyo sobre economía mundial?
- Que es el “arquetipo de la masculinidad”…
¿Por qué? ¿Será porque habla de economía y crecimiento y eso es muy masculino? Probablemente… ¿Y si resulta que la forma que tienen de aprender las máquinas por sí solas (machine learning) también contiene sesgos sexistas (y de otro tipo) que vemos en la sociedad? De eso va el artículo que han escrito Bolukbasi, Chang, Zou, Saligrama y Kalai, (Universidad de Boston y Microsoft), una referencia en este incipiente campo de investigación.
Para poder adentrarse en este mundo de los algoritmos hay que comprender un poco mejor cómo es su machine learning. Igual que los niños aprenden de sus padres, muchos algoritmos aprenden de los datos con los que se les alimenta. En el procesamiento natural del lenguaje, una de las técnicas más utilizadas consiste en cebar a la máquina con miles y miles de textos para que encuentre patrones y aprenda por sí misma el idioma. Se llama mapeo de palabras (word embedding, en inglés). “Es una red artificial para entender la estructura de una frase. La máquina se alimenta con un montón de textos que representan el lenguaje que se está estudiando”, explica Álvaro Barbero, Chief Data Scientist del Instituto de Ingeniería del Conocimiento. “El sistema aprende qué palabras están cercanas a otras y las convierte en números para que la máquina pueda entender el lenguaje. Se utiliza bastante porque es un sistema muy efectivo”.
Dicho de otra manera, lo que hace el sistema/algoritmo es agrupar palabras por temas. Algo parecido a ordenar un armario (ahora que está tan de moda), tenemos la sección abrigos, partes de arriba, camisetas, bufandas, calcetines… y luego establecemos combinaciones. ¿Pero y si la máquina nos dice al ver unos pantalones que el sujeto es un hombre? ¿Es que la mujer no puede llevar pantalones? No, es porque es más probable estadísticamente que sea un hombre.
En el artículo de Bolukbasi et al. se aborda la problemática de delegar totalmente en el machine learning sin tener en cuenta el riesgo de amplificación de los sesgos presentes en los datos.
El estudio puede resultar un primer acercamiento al mundo de los algoritmos sin ser excesivamente técnico. Además está lleno de ejemplos de cómo la técnica de mapeo de palabras nutrida con datos de Google News (la base más extensa de las que hay) está llena de prejuicios y sexismo.
“Hay cientos o incluso miles de artículos escritos sobre mapeo de palabras y sus aplicaciones, desde la búsqueda en internet al análisis de currículos. Pero ninguno de estos estudios ha reconocido lo llamativamente sexistas que son estos mapeos y el riesgo que suponen por lo tanto a la hora de introducir sesgos en sistemas del mundo real”.
Los autores digamos que juguetearon con el algoritmo de la siguiente manera:
El hombre es a un rey lo que la mujer es a “X”
X = reina (decía la máquina).
París es a Francia lo que Tokio es a “X”
X = Japón
El hombre es a programador informático lo que la mujer es a “X”
X = ama de casa
Ups… ¿Respuesta equivocada? No fue la única asociación sexista que encontraron en el sistema. También se toparon con las siguientes: Costura – Carpintería. Enfermera – Médico. Rubia – Corpulento. Diseñadora de interiores – Arquitecto. Pequeña – Alto…
“El algoritmo es naif, así que reflejará las características de la muestra. En nuestro artículo analizamos Twitter, Web Crawl, Wikipedia y Google News y encontramos diversos tipos de sesgos en todos los casos. Por ejemplo, Wikipedia tiene menos sesgo racial que Google News, mientras que el sesgo de género es generalizado en todas las bases de datos”, aclara Bolukbasi.
En el extremo del género femenino el algoritmo entrenado por Google News sitúa profesiones como: ama de casa, recepcionista, bibliotecaria, peluquera, niñera, contable… Mientras que en el lado más masculino figuran: profesor, capitán, filósofo, financiero, locutor, mago, jefe…
“En Wikipedia, Wager et al. encontraron, como sugería otro trabajo previo sobre el sesgo de género en el lenguaje, que en los artículos sobre mujeres se destacaba más su género, sus maridos, los trabajos de sus parejas y otra serie de temas que en el caso de los artículos sobre hombres se trataban mucho menos. En cuando a palabras concretas, encontraron que algunas predecían el género. Por ejemplo “marido” aparece considerablemente más a menudo en artículos sobre mujeres mientras que “béisbol” se dan más en textos sobre hombres”.
- ¿Cómo se cuantifica el sesgo?
Los autores utilizan como referencia emparejamientos neutrales: hermano – hermana, rey- reina, padre – madre. Es normal, y de esperar, que hermano esté mucho más cerca del género masculino que del femenino. ¿Pero qué pasa si la palabra médico se sitúa muy cerca del lado masculino? Solo ese dato no confirmaría el sesgo. Sí lo haría el hecho de que estuviera mucho más cerca del lado masculino que del femenino. Para saber si había sesgo o no los autores recurrieron a trabajadores de Amazon Mechanical Turk, que opinaron si determinadas relaciones de palabras les parecían sexistas.
“Hay sesgos muy habituales que relacionan términos femeninos con liberal, artístico y familiar y términos masculinos con ciencia y carreras profesionales”.

Este gráfico del estudio muestra las palabras que están contaminadas; las que están por encima de la línea horizontal. Por ejemplo: ama de casa (homemaker) está mucho más cerca del “ella” (she) que del él (he). ¿Es esto un sesgo? Claramente. Genio (genius), por el lado contrario se asocia mucho más al mundo masculino. Las palabras que están por debajo de la línea horizontal son las que tienen sentido que estén más hacia un lado u otro porque su propia definición implica ya un género.
- Así que tenemos un algoritmo infectado suelto. ¿Se puede arreglar?
Los autores proponen un sistema para solucionarlo que daría asociaciones mucho más neutrales. Estos gráficos muestran la efectividad de la corrección: en el caso de las analogías malas, se reduce tras modificar posteriormente el algoritmo (gráfico izquierda), mientras que el número de las analogías apropiadas (gráfico derecha) no se ve reducido. Las relaciones tipo padre-madre no desaparecen.
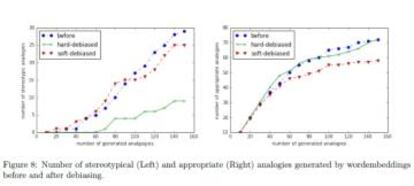
Por ejemplo: un 19% de las 150 analogías seleccionadas se consideraban sexistas. Después de aplicar la modificación (hard debiased) se redujeron al 6%. En el caso de “él es médico como ella es a X”, el algoritmo ya no dice “X = enfermera” sino “X = doctora”.
Las implicaciones de estas asociaciones sexistas pueden ir mucho más allá de lo que es correcto o no: existe el peligro de que el efecto se pueda amplificar desde la red a la vida real. Los autores ponen un hipotético ejemplo: si el algoritmo relaciona la informática más con nombres de hombres que de mujeres, entonces puede llegar a influir en los motores de búsqueda; las páginas de “José” saldrían mucho más arriba que las de “María”. “Sería todavía más difícil para una mujer ser reconocida como una informática y contribuiría a ampliar la brecha que ya hay entre hombres y mujeres en la informática”.
“Esto supone un riesgo importante y un reto para el machine learning y sus aplicaciones… En términos de palabras, la asociación al género femenino de cualquier palabra, incluso una subjetivamente positiva como podría ser 'atractiva', puede provocar discriminación contra las mujeres si reduce la asociación con otras palabras como 'profesional”.
Vivimos rodeados de muchos algoritmos cuyas fórmulas desconocemos. El reciente caso de las noticias falsas y su propagación a través de las redes sociales ya ha forzado algunos cambios matemáticos. Es difícil saber si estamos expuestos a sesgos por todas partes. “Es posible que tu solicitud de préstamo al banco, o un detector de fraude o incluso Siri tengan sesgos. Es muy difícil de decir pero estamos intentando construir un marco para saberlo y medirlo”, explica Bolukbasi.
Algunos alertan de que se está creando “la entidad más discriminadora, terca y fascista que haya conocido la raza humana; la inteligencia artificial.” Pero esa máquina con conciencia todavía no se ha creado. Tenemos eso sí, algoritmos y sus prejuicios.




























































