Por qué la victoria de López Obrador es muy probable, según las encuestas
Un error de los sondeos es posible, pero de 20 puntos es poco frecuente. En México no se han producido desviaciones así desde hace décadas

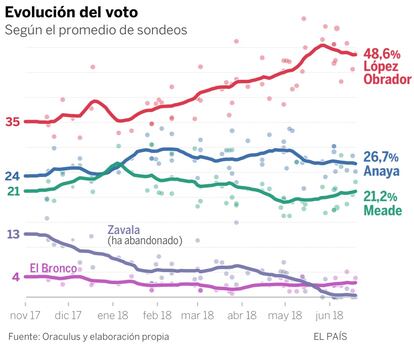
Las últimas encuestas, al cierre de esta edición, colocan a Andrés Manuel López Obrador muy cerca de convertirse en el próximo presidente de México. El promedio de sondeos lo sitúa cerca del 49% de votos el próximo domingo, mientras sus rivales quedan descolgados:Ricardo Anaya rondaría el 27% y el priista José Antonio Meade se quedaría en el 21%.
López Obrador tiene una ventaja de 22 puntos, que lo convierte en favorito. Su ventaja se ha reducido ligeramente en la última semana, pero sigue siendo amplia. De acuerdo al modelo electoral de EL PAÍS, el líder de Morena tiene un 97% de probabilidades de salir elegido presidente. Ricardo Anaya ganaría un 2% de las veces y José Antonio Meade menos del 1%. Esta es la última predicción de un modelo estadístico que venimos actualizando desde principio de 2018. El modelo promedia decenas de encuestas y tiene en cuenta la precisión histórica de los sondeos en México y otros países. La metodología es la misma que usamos en Francia, Reino Unido, España o Colombia.
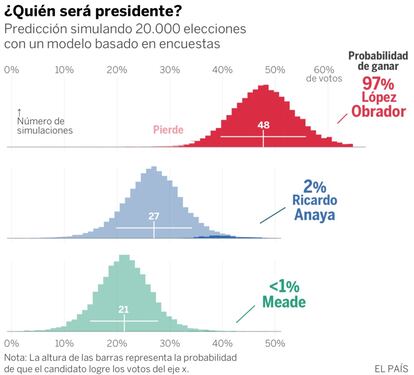
¿Qué tendría que pasar para que López Obrador no lograse la victoria? Hay dos posibilidades y ninguna es probable. La primera opción es que se produjese algún fenómeno noticioso que provocase un vuelco electoral. No obstante, faltando sólo cuatro días para la votación, y después de un larga y exhaustiva campaña, el margen para una sorpresa es ya pequeño. La otra opción con la que pueden soñar Ricardo Anaya o José Antonio Meade es que los sondeos cometiesen un error mayúsculo.
Un error de las encuestas es posible, pero un error de 20 puntos es poco frecuente. En México no se han producido desviaciones así recientemente. Desde 2006, el error de las encuestas nunca pasó de los 3 o 4 puntos en una elecciones presidenciales o legislativas. Solo en 2000 hubo un error que rozó las dos cifras. Aquel año Francisco Labastida rondaba el 46% de votos en las encuestas, pero acabó logrando sólo un 36% —casi 10 puntos menos— y perdiendo la elección contra Vicente Fox.
Los errores de 20 puntos tampoco son frecuentes en otros países. Todos tenemos en la cabeza el desacierto de los sondeos con la votación del Brexit o la elección de Donald Trump. Pero aquellos errores fueron de apenas unos puntos porcentuales. Las encuestas del Brexit fallaron sólo por tres puntos (el promedio del Financial Times, por ejemplo, daba un 49% de votos a la opción «Brexit» y acabó logrando el 52%). Aún menor fue el fallo de los sondeos en la elección presidencial de 2016 en Estados Unidos: Donald Trump rondaba en los sondeos un 45% del voto popular y acabó logrando un 46%, apenas un punto más. El único error reciente que supero los 10 puntos, al menos entre los sonados, fue el que se produjo en Colombia en 2016, cuando las encuestas minusvaloraron en 14 puntos los votos por el «no» en el plebiscito sobre los acuerdos de paz con las FARC.
Estos ejemplos sirven para explicar nuestra predicción. Nuestro modelo cree que el margen de error para López Obrador es de 11 puntos porcentuales, cuando este cuenta con una ventaja de 22 puntos sobre sus rivales. Por eso es un favorito claro para ganar el próximo domingo: porque una vuelco tan grande no es imposible, pero sí poco común.
El 1 de julio los mexicanos votarán también para escoger los diputados y senadores que renovarán sus dos cámaras legislativas. Los datos de los sondeos, analizados por EL PAÍS hace unos días, indican que el partido de López Obrador (Morena) podría ser el más votado en los dos casos y que su coalición con Encuentro Social (PES) y el Partido del Trabajo (PT) podría conseguir también la mayoría en las dos cámaras.
Metodología del modelo de la elección presidencial. Las predicciones las produce un modelo estadístico basado en sondeos y en su precisión histórica. El modelo es similar al que usamos en Francia, Reino Unido o Cataluña. Funciona en tres pasos: 1) agregar y promediar las encuestas en México, 2) incorporar la incertidumbre esperada, y 3) simular 20.000 elecciones presidenciales para calcular probabilidades.
Paso 1. Promediar las encuestas. Nuestro promedio tienen en cuenta docenas de sondeos para mejorar su precisión. Los datos han sido recopilados en su mayoría por la web Oraculus.mx. El promedio está ponderado para dar distinto peso a cada encuesta según tres factores: el tamaño de la muestra, la casa encuestadora y la fecha.
Peso por muestra. Las encuestas con más entrevistas reciben más peso, según una ley decreciente (pasado cierto umbral, hacer más entrevistas aporta poco).
Efecto de la casa encuestadora. La mayoría de encuestadoras tienden a dar mejores resultados a un candidato de forma sistemática. Es algo razonable: si usan métodos e hipótesis diferentes, es normal que sus desviaciones sean constantes. El problema es que estos efectos mueven el promedio artificialmente a corto plazo. Una opción para evitarlo es calcular los «efectos casa», la desviación sistemática de cada encuestadora con cada candidato. Después, al promediar las encuestas, sustraemos (parte de) esa desviación del dato de la encuestadora.
Encuestas repetidas. Ponderamos a la baja las encuestas repetidas de un mismo encuestador. La idea es sencilla: no queremos que una empresa que haga muchas encuestas domine el promedio. Al calcular el promedio en una fecha, la encuesta más cercana de cada encuestador tiene peso 1, y el resto un peso reducido.
Peso por fecha. El último factor es el más importante: queremos dar más peso a las encuestas recientes al calcular el promedio. Para conseguir eso asignamos pesos a los sondeos según una ley decreciente exponencial (por ejemplo, en este promedio una encuesta de hace 15 días recibe la mitad de peso que una encuesta de hoy). También definimos una franja de exclusión y eliminamos completamente las encuestas con más de 60 días de antigüedad.
Paso 2. Incorporar la incertidumbre de las encuestas. Este es el paso más complicado y más importante. Necesitamos estimar la precisión esperada de los sondeos en México. ¿De qué magnitud son los errores habituales? ¿Cómo de probable es que se produzcan errores de 2, 3 o 5 puntos? Para responder esas preguntas hemos estudiado cientos de encuestas en México y miles internacionales.
Calibrar los errores esperados. Primero he estimado el error de las encuestas en México. He construido una base de datos con encuestas de cinco elecciones desde 2000 —incluyendo las tres presidenciales. El error absoluto medio (MAE) de los promedios de encuestas en México ha rondado los 3 puntos por partido o candidato. Eso significa que fueron habituales desviaciones de 3 o 4 puntos y que el margen de error se acerca a los 8 puntos. Pero tres elecciones son pocas para extraer conclusiones fuertes, especialmente si miramos el acierto de los sondeos en la región. Nuestro análisis de 24 votaciones en Latinoamérica eleva el error MAE a 4 puntos. Por eso, queriendo ser cautos, nuestro modelo asume un MAE de 3,5 puntos para México.
Esos errores dependen al menos de dos cosas: del tamaño del candidato/partido y de la cercanía de las elecciones. Para tener en cuenta esos dos factores hemos recurrido a la base de datos de Jennings y Wlezien, recientemente publicada en Nature. Hemos analizado los errores de más de 4.100 encuestas en 241 elecciones de 19 países occidentales. Así hemos construido un modelo sencillo que estima el error MAE del promedio de votos estimado por las encuestas para cada partido, teniendo en cuenta: i) su tamaño (es más fácil estimar un partido que ronda el 5% en votos que uno que supera el 30%), y ii) los días que faltan hasta las elecciones (porque las encuestas mejoran al final).
Distribución. Para incorporar la incertidumbre al voto de cada partido en cada simulación utilizo uno distribución multivariable. Uso distribuciones t-student en lugar de normales para que tengan colas más largas (curtosis): eso hace más probable que sucedan eventos muy extremos. Las ventajas de esa hipótesis la explica Nate Silver. El nivel de curtosis lo he estimado con la base de datos. Luego defino la matriz de covarianzas de estas distribuciones para que i) la suma de los votos no sobrepase el 100% (una idea de Chris Hanretty), y ii) consideren correlaciones entre candidatos cercanos (tomando datos de duelos cara a cara y de segundas opciones). Por último, hay que escalar la amplitud de las matrices de covarianza para que las distribuciones de voto que resultan al final tengan el MAE y la amplitud esperados según la calibración.
Paso 3. Simular. El último paso consiste en ejecutar el modelo 20.000 veces. Cada iteración es una simulación de las elecciones con porcentajes de voto que varían según la distribución definida en el paso anterior. Los resultados en esas simulaciones permiten calcular las probabilidad que tiene cada candidato de ganar.
Por qué encuestas. El modelo se basa por entero en encuestas. Existe la percepción de que los sondeos no son fiables, pero a nivel nacional fallaron por pocos puntos incluso con Trump y con el Brexit. En otras elecciones recientes dieron menos que hablar porque estuvieron acertados (Francia, Países Bajos, País Vasco, Galicia, Cataluña). Pese a la creencia popular, lo cierto es que las encuestas no lo han hecho mal últimamente. Las encuestas raramente son perfectas, pero no existe una alternativa que haya demostrado mejor capacidad de predicción.
Tu suscripción se está usando en otro dispositivo
¿Quieres añadir otro usuario a tu suscripción?
Si continúas leyendo en este dispositivo, no se podrá leer en el otro.
FlechaTu suscripción se está usando en otro dispositivo y solo puedes acceder a EL PAÍS desde un dispositivo a la vez.
Si quieres compartir tu cuenta, cambia tu suscripción a la modalidad Premium, así podrás añadir otro usuario. Cada uno accederá con su propia cuenta de email, lo que os permitirá personalizar vuestra experiencia en EL PAÍS.
¿Tienes una suscripción de empresa? Accede aquí para contratar más cuentas.
En el caso de no saber quién está usando tu cuenta, te recomendamos cambiar tu contraseña aquí.
Si decides continuar compartiendo tu cuenta, este mensaje se mostrará en tu dispositivo y en el de la otra persona que está usando tu cuenta de forma indefinida, afectando a tu experiencia de lectura. Puedes consultar aquí los términos y condiciones de la suscripción digital.




























































