¿Podemos predecir la ocupación que tendrán los autobuses?
Los datos históricos y las redes neuronales facilitan la construcción de modelos de predicción para que los pasajeros puedan decidir en qué parada y en qué vehículo suben en función de la actividad que haya

Debido a la pandemia de la covid-19, muchas empresas de transporte han visto como un valor añadido la necesidad de informar a sus clientes de la ocupación con que se encontrarán al subirse a un autobús. Esta funcionalidad resulta de utilidad para frenar los contagios y para evitar aglomeraciones: si se informa con antelación a los pasajeros sobre cómo irán de llenos los vehículos, pueden optar por viajar en los que vayan más vacíos.
Dado que las empresas de autobuses suelen guardar datos e históricos de los viajes de cada vehículo, surge la posibilidad de abordar el problema con técnicas de inteligencia artificial basada en datos. En concreto, con el aprendizaje supervisado, en el que se construye un modelo predictivo al que se entrena con datos históricos que se etiquetan de alguna manera. A partir de dichos datos, el modelo detecta ocurrencias de patrones. Por ejemplo, que el autobús de las ocho y media suele ir lleno los días laborables. Así, va siendo capaz de hacer predicciones a futuro.
Al juntar datos históricos de ocupación y validaciones de los usuarios con la información de las líneas de autobús y del calendario, ya se dispondría de los datos necesarios para modelar el comportamiento de los pasajeros.
¿Qué significa entrenar un modelo?
Cuando hablamos de entrenar una red neuronal, lo que en realidad queremos es ajustar los parámetros de una función (red neuronal) para que aprenda una tarea concreta. Es decir, que para que aprenda a obtener unas salidas a partir de unas entradas.
Esto se consigue suministrando como entrada, durante la fase de entrenamiento, grandes cantidades de datos, de modo que se va minimizando el error de predicción del modelo a base de ir ajustando sus parámetros internos. El proceso de entrenamiento de una red neuronal se basa principalmente en la ingeniosa aplicación de La regla de la cadena, que se suele enseñar para derivar en matemáticas. Esta regla nos permite calcular cómo se deben ir modificando los parámetros de la red para minimizar el error de predicción iterativamente.
En este caso, se pretende que el modelo aprenda a calcular la ocupación de los buses en cada una de las paradas por donde pasan. Para ello, al modelo se le debe dar como entrada una representación numérica (vectores) de la información del autobús, la parada, el calendario, etc., y se pretende que nos devuelva el número de pasajeros que habrá, tal como se muestra en la siguiente imagen. Con históricos de unos pocos meses ya se puede llegar a obtener una predicción bastante buena.
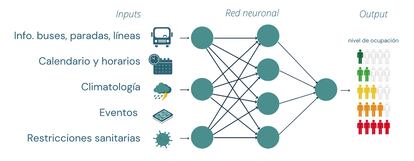
La gracia de utilizar redes neuronales es que permiten, con un único modelo, hacer predicciones sobre cualquiera de las líneas de autobús en cada una de sus paradas, sin tener que hacer un modelo o algoritmo especializado para cada una de las líneas. Esto facilita su aplicación en otras ciudades, donde las líneas y las paradas serán completamente distintas.
Series temporales: redes neuronales recurrentes
Sin embargo, se puede llegar a hacerlo mejor. El modelo que acabamos de presentar no tiene en cuenta la ocupación previa de las paradas anteriores, que resulta una información muy relevante, y saberla puede condicionar mucho la ocupación de la próxima parada.
Para estos tipos de problemas donde se tratan secuencias, hay un tipo de redes neuronales llamadas redes recurrentes (recurrent neural networks), que nos permiten trabajar con series temporales teniendo en cuenta los valores anteriores de ocupación para predecir la de la siguiente parada. Lo que hacen estas redes, en resumen, es ir codificando la información de las paradas previas de forma compacta para, finalmente, obtener un vector resultante que contiene toda la información comprimida de toda secuencia. De esta manera, el modelo puede llegar a captar mejor los cambios y patrones temporales y así obtener mejores resultados.
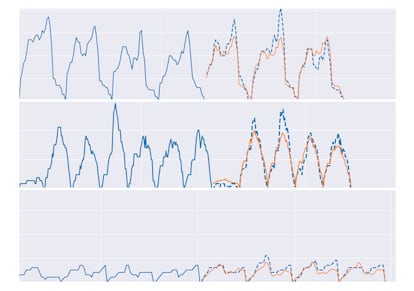
¿Y cómo son las predicciones? En la imagen que se muestra algo más adelante puede verse un ejemplo de lo que el modelo predice para diferentes autobuses: el eje de las x es el eje temporal y de las y representa la ocupación del bus. Se puede ver cómo la ocupación de los vehículos empieza en cero al inicio del viaje, va subiendo y vuelve a bajar a cero cuando finalizan su trayecto. Y así sucesivamente, como se aprecia por las “colinas” que se forman en el gráfico. La línea azul hace referencia a la ocupación real (según los datos históricos) y la línea naranja representa las predicciones a futuro de la red neuronal, en la que observamos que acierta bastante con la ocupación real de viajes futuros, obteniendo un error promedio de dos personas por parada.
Los modelos basados en redes neuronales son muy versátiles y permiten resolver una gran diversidad de problemas de manera muy eficaz y precisa si disponemos de los datos necesarios. Con estas técnicas, inLab FIB, el laboratorio de innovación de la Facultat d’Informàtica de Barcelona (FIB) de la Universitat Politècnica de Catalunya (UPC), junto a la empresa de ingeniería de movilidad inteligente y ticketing Ityneri by Geoactio, ha desarrollado una solución que ya está informando las 24 horas del día y los siete días de la semana a los usuarios de algunas ciudades españolas sobre las predicciones de ocupación en la flota de autobuses.
Albert Obiols es responsable del área de data science y big data, inLab FIB, de la Universidad Politénica de Catalunya (UPC).
Gonzalo Recio es senior data scientist en el inLab FIB de la UPC.
Crónicas del Intangible es un espacio de divulgación sobre las ciencias de la computación, coordinado por la sociedad académica SISTEDES (Sociedad de Ingeniería de Software y de Tecnologías de Desarrollo de Software). El intangible es la parte no material de los sistemas informáticos (es decir, el software), y aquí se relatan su historia y su devenir. Los autores son profesores de las universidades españolas, coordinados por Ricardo Peña Marí (catedrático de la Universidad Complutense de Madrid) y Macario Polo Usaola (profesor titular de la Universidad de Castilla-La Mancha).
Puedes seguir a EL PAÍS TECNOLOGÍA en Facebook y Twitter o apuntarte aquí para recibir nuestra newsletter semanal.




























































